Text Classification
This lesson will teach you how to perform text classification with the Naive Bayes algorithm.
Naive Bayes
In the previous lesson on sentiment analysis, you learned how to classify text using VADER. VADER actually uses unsupervised machine learning, as it involves a rule-based approach instead of using target data to train with.
In this lesson, we will be using a supervised machine learning algorithm to classify video game reviews as positive or negative. Basically, we are creating our own specific sentiment analysis lexicon specifically for video games reviews. This machine learning algorithm we will use is called Naive Bayes.
Setup
Start by creating a new project called TextClassification, then create a new python file called classifier.py.
Create a folder called Datasets and download the Gamespot Game Reviews dataset by saving it in the Datasets folder.
Note: If you took the first part of this course where you already performed analysis on this dataset, you are welcome to follow the steps with a different dataset of your own choosing.
If you are up for a challenge, you can try to clean up and perform analysis on a Movies Reviews Dataset. The data is stored in separate files underneath a folder structure, so you will need to clean up the data before it can be used in your algorithm, as an added challenge.

Now, let's import the modules that we will use and read in the CSV file.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
df = pd.read_csv("Datasets/gamespot_game_reviews.csv")
Here we import the usual numpy and pandas. We also import train_test_split again in order to split our data into training and testing groups.
However we have a few new modules imported this time:
CountVectorizer - This module will allow us to count the number of times a token (word) appears in the text.
TfidfTransformer - This module will filter out words that occur too frequently and thus do not give useful information, such as 'the', 'or', 'and'.
MultinomialNB - This module will allow us to train and test our data using the Naive Bayes MultinomialNB algorithm.
Next, we'll start to look at the data set and structure it in a way we can use it for our machine learning purposes.
Data Analysis
Let's start by looking at all the columns in the dataset.
df = pd.read_csv("gamespot_game_reviews.csv")
print(df.columns)

For the purposes of our classification, we're going to use two columns: 'tagline' and 'classifier'. We'll create a new dataframe that has just those columns.
df = pd.read_csv("Dataset/gamespot_game_reviews.csv")
reviews_df = df[['tagline', 'classifier']]
print(reviews_df)

Based on the data, we can see that the tagline is the review of a game, and the classifier is one of two values:
posor
neg, indicating a positive or negative review.
Next, we're going to need to break down the tagline field to get at the words which really matter for the classifier.
Understanding Text
First, we need a way to count how often words appear inside of a 'tagline' field. The CountVectorizer will count how many times a word appears in a specific line.
By using the CountVectorizer, we take the list of text strings, and count how many times a word appears in the string.
In order for the machine learning to occur, it takes all of the strings and transforms them into numbers.
reviews_df = df[['tagline', 'classifier']]
tagline_list = reviews_df['tagline'].tolist()
count_vect = CountVectorizer()
x_train_counts = count_vect.fit_transform(tagline_list)
print(x_train_counts)
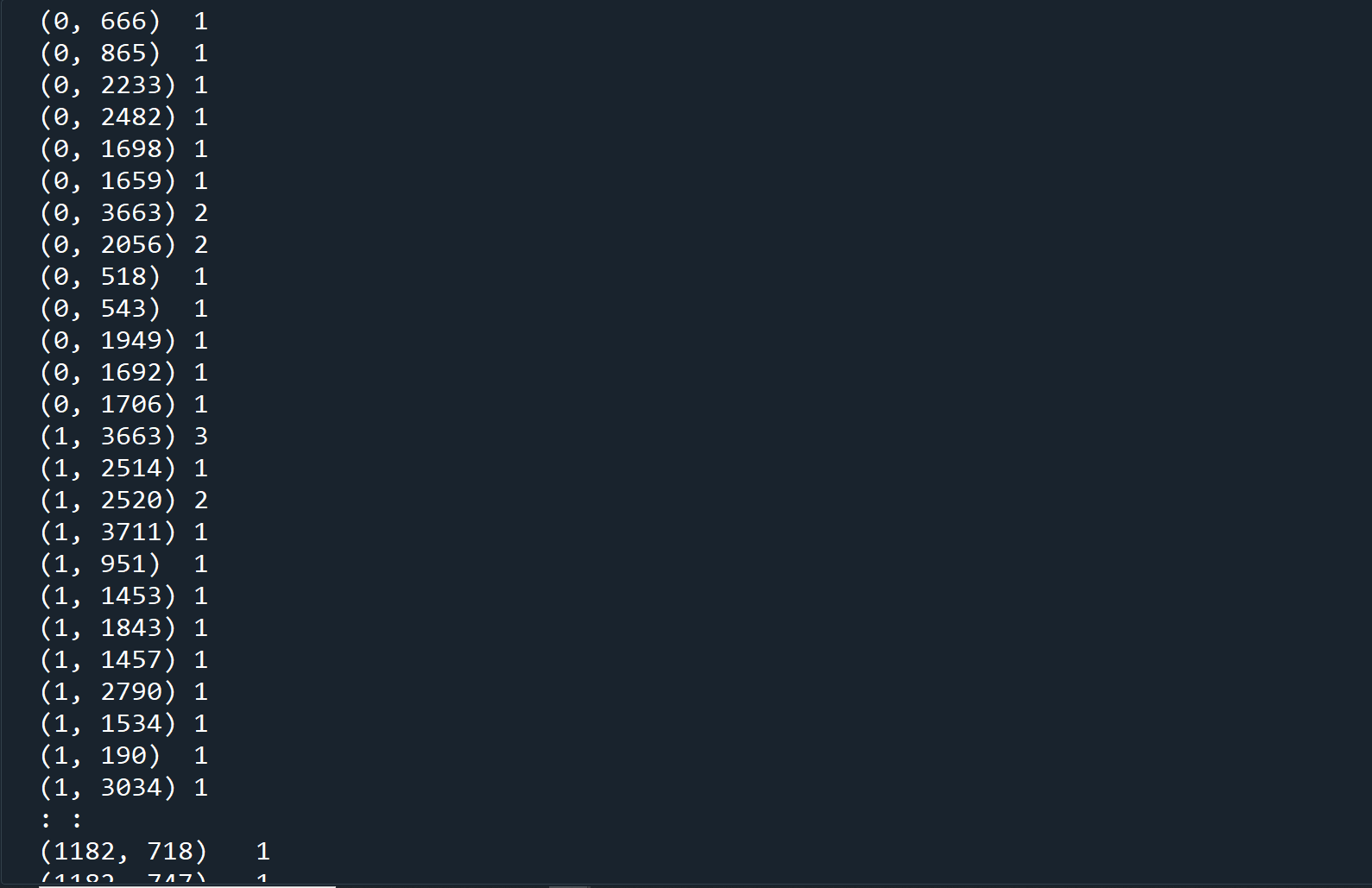
The results shows a tuple column and an integer column. The tuple contains two elements, the first element is the index of the tagline field, and the second is the word (represented as a number). The second column shows how many times the word appeared in that tagline.
Next, we're going to set up information related to the weight of each word, or how often it appears in the text. We'll do this using TFIDF, or
Term Frequency -Inverse Document Frequency.
TFIDF will give each word an
importancescore. It uses a strategy of finding words that are shared across multiple taglines, but don't appear everywhere. For example, it will give a low weight to the word
thebecause it appears everywhere. But it will give a high weight to a word like
amazing, which isn't common to every single tagline, but is shared by 15 different reviews. That means it's an important word these reviews use to describe a particular quality of the game.
TFIDF determines a word's importance inside of a dataset, but it doesn't tell us whether the word means the game is good or bad. In fact, the word
terriblealso appears in 15 reviews, so TFIDF will give the words
amazingand
terriblethe exact same weight. Our machine learning algorithm will use these weights to determine which of these words indicates a positive or negative review.
x_train_counts = count_vect.fit_transform(tagline_list)
tfidf = TfidfTransformer()
x_train_tfidf = tfidf.fit_transform(x_train_counts)
With our data ready to go, we can now start to do our machine learning on this data set.
Train, Predict, Test
Once again, we're going to use the train_test_split() function to split up our data into different parts.
x_train_counts = count_vect.fit_transform(tagline_list)
tfidf = TfidfTransformer()
x_train_tfidf = tfidf.fit_transform(x_train_counts)
X_train, X_test, y_train, y_test = train_test_split(
x_train_tfidf,
np.array(reviews_df['classifier']),
test_size=0.3,
random_state=0)
The last step is to actually apply the machine learning model, and perform predictions using our test data.
classification_model = MultinomialNB().fit(X_train, y_train) y_pred = classification_model.predict(X_test) print(y_pred)
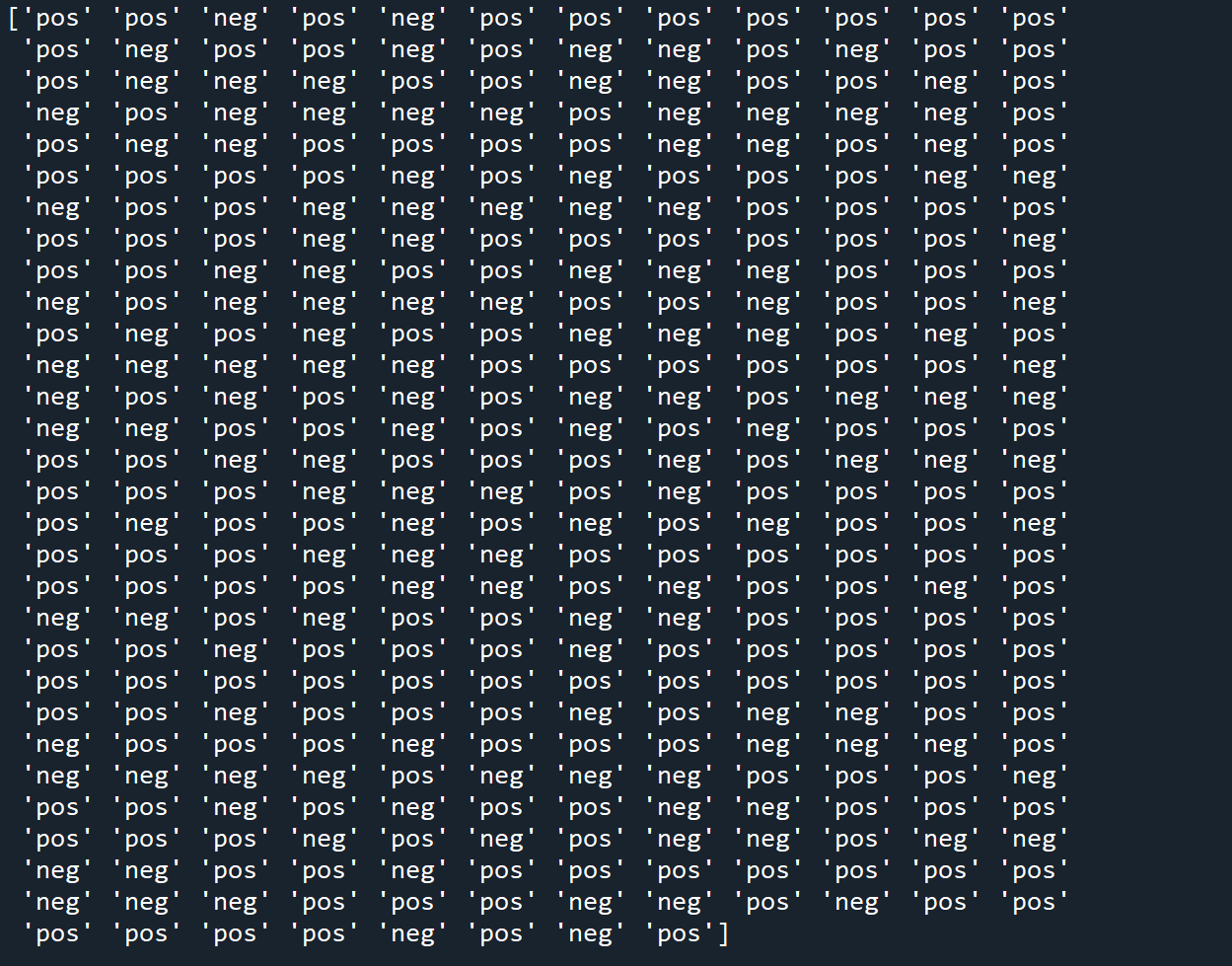
In the output for y_pred we see the results of the prediction. We can compare these against the test data set to determine the accuracy of our model.
y_pred = classification_model.predict(X_test)
number_right = 0
for i in range(len(y_pred)):
if y_pred[i] == y_test[i]:
number_right +=1
print("Accuracy for tagline classify: %.2f%%" % ((number_right/float(len(y_test)) * 100)))

Our model has an accuracy of 79.78%!
Activity: Interactivity
- Have the program train the model, just like before.
- Then, have the program ask the user to write a review of the game.
- Run the user input through the prediction to get a result, and display that back to the user.
Right now, you have a program that takes in a dataset and gives a prediction based on information already in the dataset.
But to make this program really useful, we should allow the user to type in their own review of a game, and have the algorithm predict whether the review is positive or negative.
This is an application that could be used to look at reviews and comments of games by players and determine whether or not the reviews are positive or negative.
To set up this program:
Based on the results, you may want to alter your dataset to make it more accurate. You can even add more data to the dataset manually, if you have any review results you can manually label.