Supervised Learning Algorithms
This lesson will teach you about supervised learning algorithms and the Random Forest Model.
Supervised Machine Learning
In machine learning, there are 3 main types of learning algorithms:
Supervised Learning: Most machine learning algorithms are used for supervised learning. This is where you have input variables (independent data) that is used to predict an output variable (dependent data). This is useful when humans can reliably predict output based on inputs, such as labeling what types of objects are in a picture.
Unsupervised Learning: Sometimes, you may write programs that don't have exactly
Reinforcement Learning: You might develop an AI that continually learns over time, rather than receiving training only at one time. In the reinforcement learning approach, the model is continually updated as it learns about its environment. Think about an AI that learns how to navigate a maze. Every time the AI navigates the maze, you give it a reward based on how fast it traversed the maze. That way, it can learn the fastest path through the maze.
Unsupervised Learning: Sometimes, you may write programs that don't have exactly
correctoutputs that can be derived from inputs. Unsupervised Learning is commonly used for programs that have creative outputs, such as writing stories or songs.
Reinforcement Learning: You might develop an AI that continually learns over time, rather than receiving training only at one time. In the reinforcement learning approach, the model is continually updated as it learns about its environment. Think about an AI that learns how to navigate a maze. Every time the AI navigates the maze, you give it a reward based on how fast it traversed the maze. That way, it can learn the fastest path through the maze.
For now we will just look at supervised learning. This is the most reliable and testable way of implementing machine learning.
Supervised Learning
In supervised learning, we create a training set, which takes in a set of input variables with the matching output variable, and feed this set into the algorithm. The algorithm then learns by mapping the input to output so that it can later predict an output based on some input it hasn't seen yet.
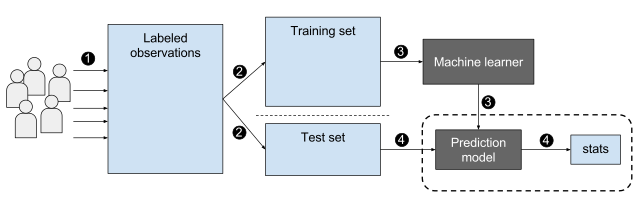
"Machine learning nutshell", by Epochfail, licensed under CC BY-SA 4.0
It is called supervised learning because we can think of the training dataset as a teacher that supervises the learning process.{kind=link}
The algorithm iteratively makes predictions on the training data and is corrected by the teacher who knows the answers. Learning stops when the algorithm reaches an acceptable level of predictive accuracy.
Supervised learning can be further split into two types of problems:
Classification: This is when the output variable is a category, e.g.
redor
blueor
maleor
female. When you perform classification, all your outputs must be EXACTLY matched to a category in a set.
Regression: This is when the output variable is a value inside of a range, e.g.
dollarsor
height. For example, you can have 0 dollars, 100 dollars, 1.5 dollars, or other decimal values for your output variable.
Some of the most popular examples of supervised learning algorithms are:
Linear Regression for regression problems.
Random Forest for classification and regression problems.
Support Vector Machines for classification problems.
We will start of by looking at the Random Forest Algorithm.
Random Forest Algorithm
Random Forest is a supervised machine learning algorithm that uses an ensemble technique. This technique joins different types of algorithms or the same algorithm many times to create a powerful prediction model.
The random forest algorithm combines many decision trees (hence the name random forest) in order to perform both regression and classification tasks.
The creation and combination of multiple decision trees to make a final prediction is called Bootstrap Aggregation (commonly referred to as bagging).
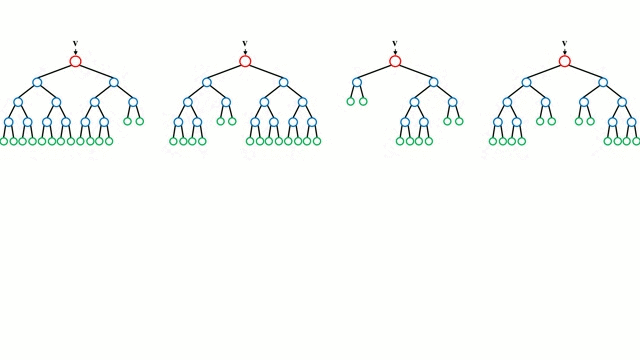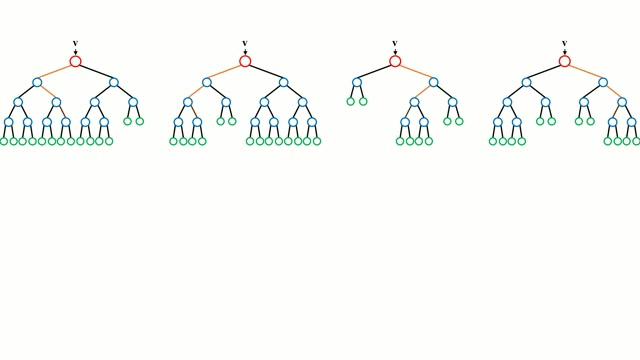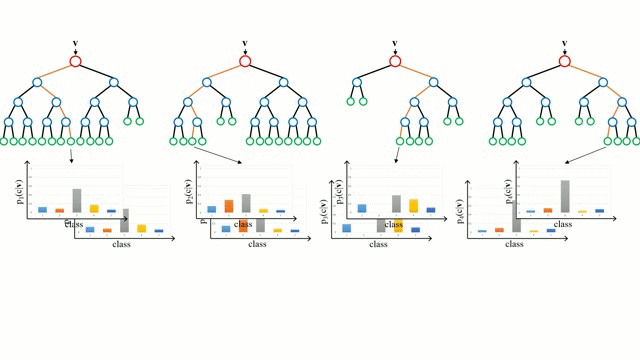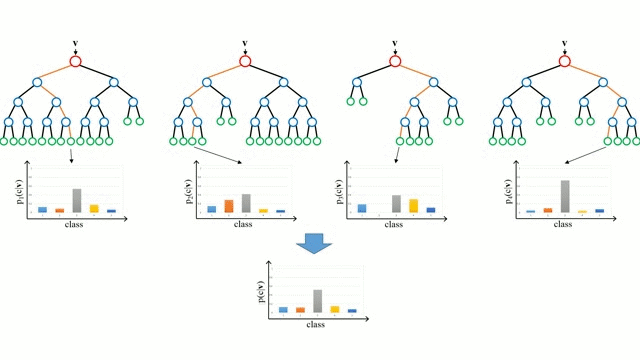
"Random Forests Ensemble", by Hgkim0331, licensed under CC BY-SA 4.0
Here's how it works:{kind=link}
1. Pick N random records from the dataset.
2. Build a decision tree based on these N records.
3. Choose the number of trees you want in your algorithm and repeat steps 1 and 2.
4a. In regression problems, for a new record, make each tree predict the output for the record. The final output for that record is the average of the predicted outputs from each individual tree.
4b. In classification problems, each tree predicts the category that the new record belongs to. The new record is assigned to the category that has the majority of predictions.
| Advantages of Random Forest | Disadvantages of Random Forest |
|---|---|
| Not biased since there are multiple trees, each trained on a subset of data. | Requires a lot of computational resources because of the complexity |
| Very stable algorithm since new data or outliers may impact one tree but is unlikely to impact all trees. | Takes a relatively long time to train large amounts of data due to the complexity. |
| Works well with both categorical and numerical features. |