Processing Webpage Content
This lesson will teach you how to process webpage content using the natural language tool kit(NLTK).
Setup
Now that you're able to scrape data from webpages, let's learn how to process this data for machine learning applications.
If you recall, natural language processing (NLP) is the field of artificial intelligence in which computers analyze, understand, and derive meaning from human language in a smart and useful way.
First, create a new project in Spyder and save it as NaturalLanguageProcessing.
Then, create a new file inside the project and save it as processing.py. You can also delete the text that's already in the file.

Now, let's import our modules:
Requests
BeautifulSoup 4
import requests
from bs4 import BeautifulSoup
We still need to import one more module which will provide us with the necessary tools to actually process natural language.
This module is NLTK (Natural Language ToolKit) and is the most popular libraries for natural language processing.
import requests
from bs4 import BeautifulSoup
import nltk
NLTK comes with many corpora (collections of written texts), nlp models, and other data packages.
We can download this data into our project using the nltk.download() method.
import nltk
nltk.download()
Now run your program and another window should pop up. This is the NLTK downloader which allows you to choose which packages you want to download from the NLTK library.
Since the packages have small sizes we are just going to install all packages.
The downloads may take a bit of time so wait for them to finish. You will see downloads in process highlighted in yellow and completed downloads highlighted in green.
We also need to get a webpage so that we can process its content. We will be processing a Wikipedia page about Nintendo.
Just like before, we will use Requests to download the page.
import nltk
nintendo_wiki = 'https://en.wikipedia.org/wiki/Nintendo'
page = requests.get(nintendo_wiki)
print(page.text)
As you can see, we successfully downloaded the page. Now let's use BeautifulSoup to parse and clean it.
Remember, you can clear the console when it gets filled up by right clicking in the window and selecting Clear console.
Alternatively you can left click in the console then press CTRL + L on your keyboard.
nintendo_wiki = 'https://en.wikipedia.org/wiki/Nintendo'
page = requests.get(nintendo_wiki)
soup = BeautifulSoup(page.text, 'html.parser')
Last time we wanted to keep the tags so that we could locate specific parts of the page. This time we are only going to extract the text for processing because the tags are not natural language (human language).
We can do this using the soup.get_text() method to get just the text.
soup = BeautifulSoup(page.text, 'html.parser') text = soup.get_text() print(text)
As you can see, we now only have the text from the page without all the tags.
Although it is nice and easy for us to read, a computer doesn't need the text to be separated this much. All the computer needs is a space between each word so that they can be differentiated as separate words.
Therefore we can remove the extra whitespace from the text by setting the strip parameter to True, while keeping a space between each individual word by setting the separator parameter to ' ' (a space).
soup = BeautifulSoup(page.text, 'html.parser') text = soup.get_text(separator = ' ', strip = True) print(text)
Now we have only the text without all the unnecessary whitespace.
Finally, it's time to start natural language processing.
Python Tokenization
- Project Gutenberg has texts from the public domain of fiction and non-fiction.
- Kaggle has datasets for text that can go through this type of cleanup too.
Tokenization is when you divide a piece of text into tokens. These tokens can be words, sentences, paragraphs or whatever you want.
Tokenization is usually the first task performed in natural language processing, so that's what we will do first.
As you may recall, tokenization can be performed at two levels: word-level and sentence-level.
Word-level
At the word-level, tokenization returns a set of words from a sentence.
For example, tokenizing the sentence
My name is Davidreturns the following set of words:
words = ['My', 'name', 'is', 'David']
At the sentence-level, tokenization returns a set of sentences from a document.
For example, tokenizing the document with the text:
My name is David. I am 21 years old. I live in the UK.returns the following set of sentences:
S1 =
S2 =
S3 =
My name is David.
S2 =
I am 21 years old.
S3 =
I live in the UK.
For this example, we are going to do word level tokenization. We can do this using the Python string split() method.
This method splits a string into a list where each word is a list item. By default, the method will split words separated by whitespace.
soup = BeautifulSoup(page.text, 'html.parser') text = soup.get_text(separator = ' ', strip = True) words = text.split() print (words)
As you can see we now have a long list of all the words from the wikipedia article. Let's see how many words we have in total.
words = text.split() print (len(words))

In this example, the whole page has 18,785 words in total (Your count may be a little different, if the page has changed, but it should be close to that number.) However, keep in mind that these are not 18,785 unique words. You will also soon find out that some of the things counted are not actually words.
Frequency Distribution
In NLP, it is common to count the frequency of words in text in order for the program to understand what words are important in the context of the document. NLTK allows us to do this easily with its FreqDist() function.
FreqDist is short for frequency distribution which, in this context, refers to the distribution of words in a text based on the number of times they appear.
words = text.split() freq = nltk.FreqDist(words)
This returns a FreqDist object that contains a dictionary which stores the tokens as keys and the counts of each token as values.
We can display the frequency distributions using the items() method which returns a list of tuples containing a word and its respective frequency.
freq = nltk.FreqDist(words) print(freq.items())
As you can see, we get a long list of tuples containing each word from the text along with the number of times it appears (the frequency). We can actually plot of graph that displays the frequency distribution of each word. This is called a Frequency Distribution Graph.
We can plot this using NLTK's plot() function and pass an integer into the function as an argument that specifies how many tokens to display.
By default, the plot displays tokens in the order of descending frequency. Let's display the 20 most common words from the text. We can also specify the title of the graph with the title parameter.
freq = nltk.FreqDist(words) freq.plot(20, title = 'Frequency Distribution')
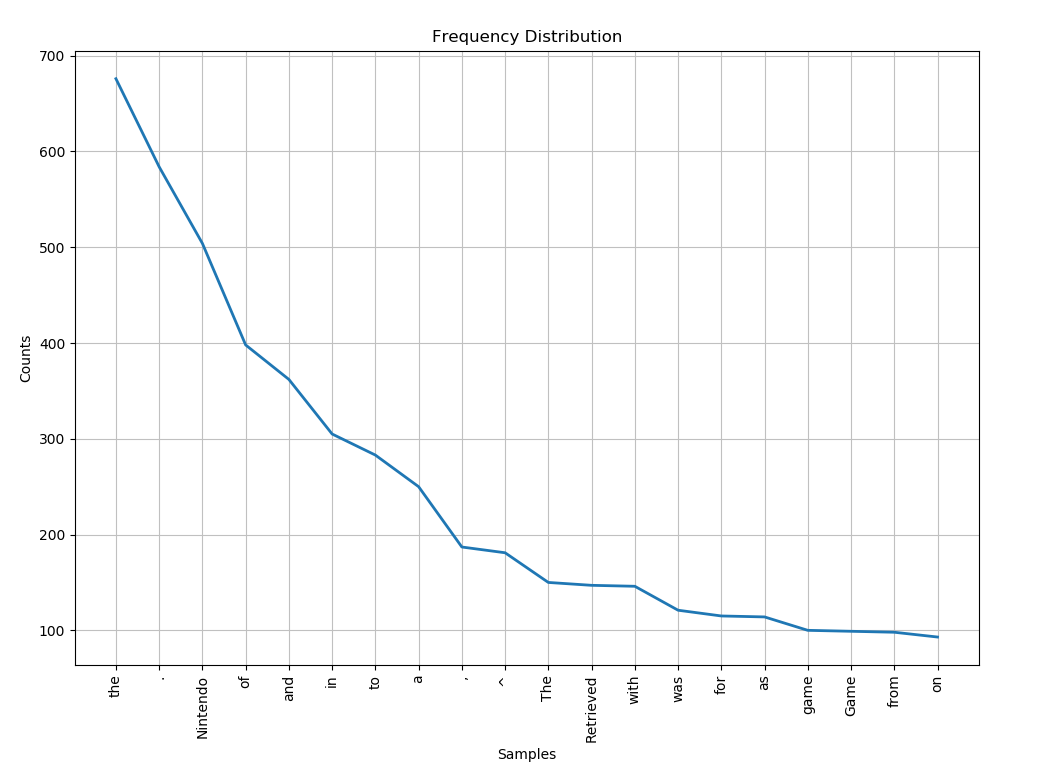
Open the plots tab and you will see that the graph shows the words that are used most in the text, from highest to lowest frequency. However, it also shows some problems with our frequency distribution that we need to fix.
1. The same words appear multiple time with different capitalization, such as 'game' and 'Game'.
2. Punctuation and special characters are also counted.
3. Words that do not provide useful information are also counted, such as 'the', 'of', 'in', 'and', etc.
1. Changing Case:
The program counts words by selecting a word and counting how many times the exact same word reappears. Unfortunately, this means that if the same words appear with both uppercase and lowercase letters, they will be considered different because case is taken into account.
Therefore, we need to change all the words to the same case so that we do not get multiple different frequencies for the same word.
To do this, we can use Python's lower() function which returns a string where all the characters are in lowercase. Let's go back and make our text lowercase before we split it up.
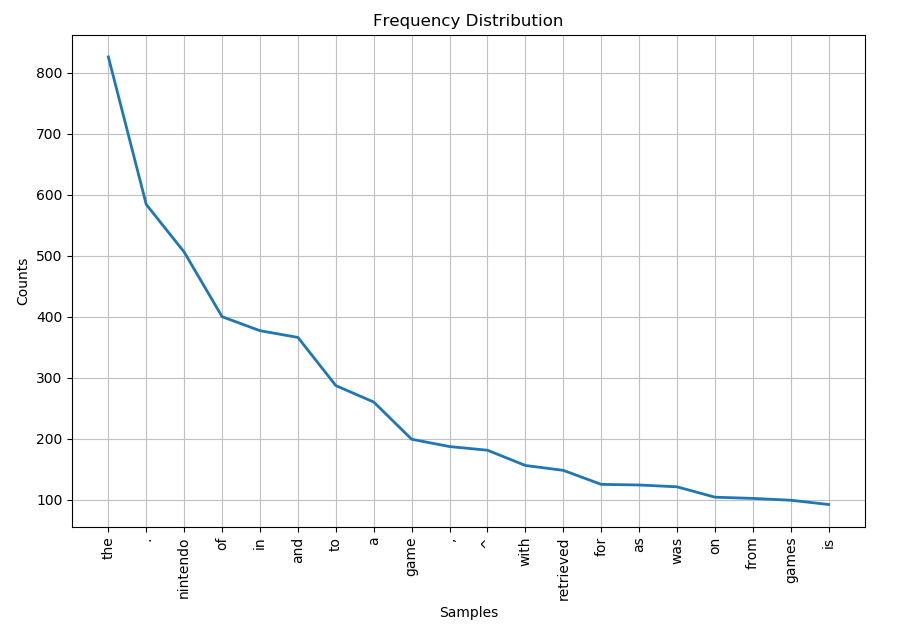
soup = BeautifulSoup(page.text, 'html.parser') text = soup.get_text(separator = ' ', strip = True) clean_text = text.lower() words = clean_text.split()
Here we create a new string called clean_text which is just our original text but all in lowercase. Make sure to split the new string using clean_words.split() instead of the old words.split().
Now if we run the program again and look at the new graph, the duplicate words are removed.
2. Removing Punctuation:
Recall from before when we displayed the word count and saw 18,785 words and it was mentioned that some of the elements counted were not actually words? Well, it turns out that the punctuation in the text was counted as separate
words.
We don't want to analyze punctuation or count them in our frequency distribution. We can remove punctuation using Python's maketrans() and translate().
Translate means to convert or change and the translate() method will do the same thing. It will convert/change a string by altering the characters in the string.
A string can be translated with the translate() method by:
1. Inserting characters into the string
2. Replacing characters in the string
3. Deleting characters in the string
How the translate() method changes the string depends on a translation table which we will create with the maketrans() method.
A translation table is just a dictionary that gives the translation for each character in a string. We can use the maketrans() method to create a translation table using the following syntax:
string.maketrans(x,y,z)
# y and z are optional
There are 3 different ways to use this method:
Passing in 1 argument (x)
Passing in 2 arguments(x,y)
Passing in 3 arguments(x,y,z)
One Argument
If you pass in 1 argument, it will have to be a dictionary. In the dictionary, the keys must be characters and the values must be characters or strings.
The value should be what we want to replace the key with.
example = 'abcde'
dict1 = {'a':'1', 'b':'2'}
table = string.maketrans(dict1)
Here, maketrans() returns a translation table which is stored in table.
This table shows how characters should be replaced when we use the translate() method. E.g. 'a' should be replaced with '1' and 'b' should be replaced with '2'.
Two Arguments
If you pass in 2 arguments, then both arguments should be strings of the same length (same number of characters).
example = 'howdy boys and girls of the class'
str1 = 'abcde' #length of 5
str2 = '12345' #also length of 5
table = string.maketrans(str1, str2)
The first string should contain the old characters to replace, and the second string should contain the new characters that will replace the old ones. Again, maketrans() returns a translation table which is stored in table.
This table shows how characters should be replaced when we use the translate() method, based on the two strings passed in. E.g. 'a' should be replaced with '1' and 'b' should be replaced with '2'.
Three Arguments
If you pass in 3 arguments, then the first 2 arguments should be strings of the same length where the characters in the second string should replace the characters in the first string (the same as if we only passed in 2 arguments).
However with 3 arguments, the third argument must be a string of all the characters you want to remove.
example = '((howdy boy$s& and girls of the class%'
str1 = 'abcde' #length of 5
str2 = '12345' #also length of 5
str3 = '($&%'
table = string.maketrans(str1, str2, str3)
Once again, maketrans() returns a translation table.
This table shows how characters should be replaced and which characters should be removed when we use the translate() method, based on the three strings passed in. E.g. 'a' should be replaced with '1' and 'b' should be replaced with '2' etc. Also, all the characters in '($&%' should be removed.
translate()
After we have created the translation table, we can pass it into the translate() method that is being called by the string we want to translate.
The translate() method will return a copy of the string with each character translated according to the translation table.
example = '((howdy boy$s& and girls of the class%'
str1 = 'abcde' #length of 5
str2 = '12345' #also length of 5
str3 = '($&%'
table = string.maketrans(str1, str2, str3)
newstr = example.translate(table)
print(newstr)
#output: 'how4y 2oys 1n4 girls of th5 3l1ss'
In this example we translated the example string by replacing and deleting characters based on the translation table.
Now let's actually use these methods to remove the special characters from our list of words.
Since we are only going to remove characters and not replace any, we can pass three arguments into the maketrans() function where the first two arguments are empty strings ('') and the third argument is a list of all punctuation we want to remove.
Luckily, Python's String module provides a constant called string.punctuation which is a list of punctuation characters.
First we have to import the String package, so go back up to the top of the file and add this line.
import nltk
import string
The next step is to create our translation table.
clean_text = clean_text.lower()
table = str.maketrans('', '', string.punctuation)
Here we pass in two empty strings since we will make no replacements. We then pass in string.punctuation, which is what we will remove.
Finally we can call the translate() method on our string of words to remove the punctuation and special characters.
clean_text = text.lower()
table = str.maketrans('', '', string.punctuation)
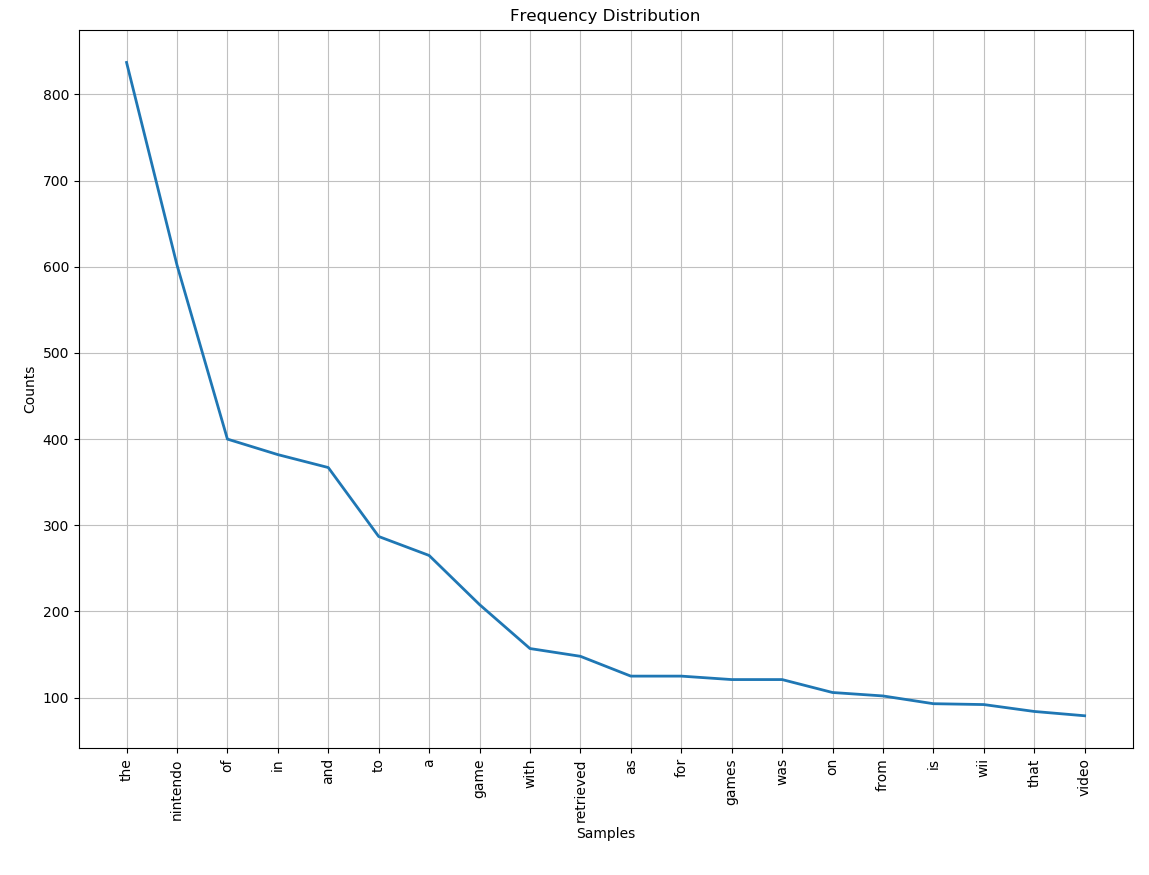
clean_text = clean_text.translate(table)
words = clean_text.split()
Here we use translate() on our clean_text, passing in the translation table as an argument. We then update the original clean_text string with the newly translated clean_text string.
Now if we run the program again and look at the new graph, the special characters are removed.
3. Stop Words:
The last thing we need to do is remove stop words.
Stop words are words that do not provide useful information in the given context. For example, 'the', 'of', 'in', 'and', etc.
We can remove these words by creating a new list that doesn't contain any stop words.
To do this, we can loop through all the words in our words list, check each word to see if it is a stop word, and only append the words to the new list that are not stop words.
Luckily, nltk has a handy list of common stop words so we can import that and use it to check the words in our list.
import nltk
import string
from nltk.corpus import stopwords
Next, we can create a new list that we will be appending our useful words to.
words = clean_text.split() clean_words = [] freq = nltk.FreqDist(words)
Now, we can create a loop that goes through every item in our words list and checks to make sure that the item is not also in the stopwords list.
We will specifically be checking for English stopwords so will use the stopwords.words('english') list.
words = clean_text.split()
clean_words = []
for token in words:
if token not in stopwords.words('english'):
freq = nltk.FreqDist(words)
Finally, if the word is not in the stopwords list, then we will append it to the clean_words list.
words = clean_text.split()
clean_words = []
for token in words:
if token not in stopwords.words('english'):
clean_words.append(token)
freq = nltk.FreqDist(words)
Now we have our new list which does not contain any stop words.
Let's now pass this list into the nltk.FreqDist() function to create a plot for this list of words instead of the old list.
words = clean_text.split()
clean_words = []
for token in words:
if token not in stopwords.words('english'):
clean_words.append(token)
freq = nltk.FreqDist(clean_words)
Now run the program again. It will take a slightly longer time to load because the program has to loop through and check every word in our list (over 18,000) for stopwords.
When the plot loads, you will see that all of the stopwords are removed.
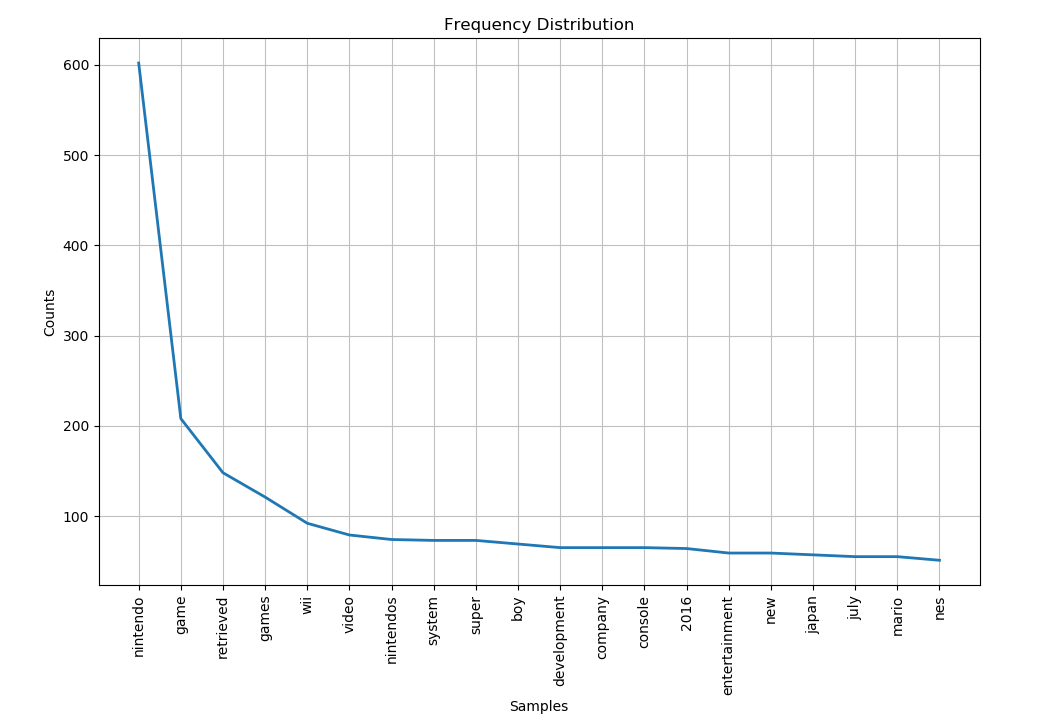
After cleaning up our data, it is now much easier to see a meaningful distribution of the most used words in the wikipedia article.
Unsurprisingly, the most used word in the article (ignoring stopwords) is Nintendo with around 600 uses!
Reminder: you can also write this for loop in one line by using a filter and a lambda function.
clean_words = list(filter(lambda word: word not in stopwords.words('english'), words))
NLTK Tokenization
Earlier you learned how to split the text into tokens (tokenization) using the split() function. Now let's learn how we can use NLTK to tokenize text.
NLTK includes both a sentence tokenizer (splitting text into sentences) and a word tokenizer (splitting text into words).
First, let's comment out our FreqDist creation and our plotting function since we don't need to create a new graph every time we run the program.
#freq = nltk.FreqDist(clean_words) #freq.plot(20, title = 'Frequency Distribution')
We can also comment out the loop here since we only needed it to get clean words for our frequency distribution.
However since we aren't plotting the frequency distribution anymore and this loop makes our program slow, we can just comment it out.
#for token in words:
# if token not in stopwords.words('english'):
# clean_words.append(token)
#freq = nltk.FreqDist(clean_words)
Now, let's go back to the top of the script and import sent_tokenize and word_tokenize from nltk.tokenize.
These are NLTK's sentence and word tokenizers.
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
Now, let's tokenize sentences and words from the original text. We will use the original text instead of the cleaned_text because we want to keep the uppercases and punctuation for our sentences.
To tokenize a string into sentences, we simply use the sent_tokenize() method and pass in the string we want to tokenize as an argument.
#freq.plot(20, title = 'Frequency Distribution') sentences = sent_tokenize(text) print(sentences)
Now we have a list of all the sentences from the text.
Print the 4th sentence in the list (index 3) to see what it says.
Note: The result you receive may be different if the web page has changed. You will still see a sentence, but it will not be the same sentence as shown in this example.
sentences = sent_tokenize(text) print(sentences[3])

Great, We have a sentence! If you look at the wikipedia page, you will notice that this is actually the second sentence of the first paragraph.

NLTK does a good job of tokenizing sentences based on certain punctuation, such as periods, exclamation marks, and question marks. However, this means that places where the text isn't split by punctuation results in sentences not being separated properly.
Index 6 of the sentences list contains the actual first sentence of the paragraph.
sentences = sent_tokenize(text) print(sentences[6])
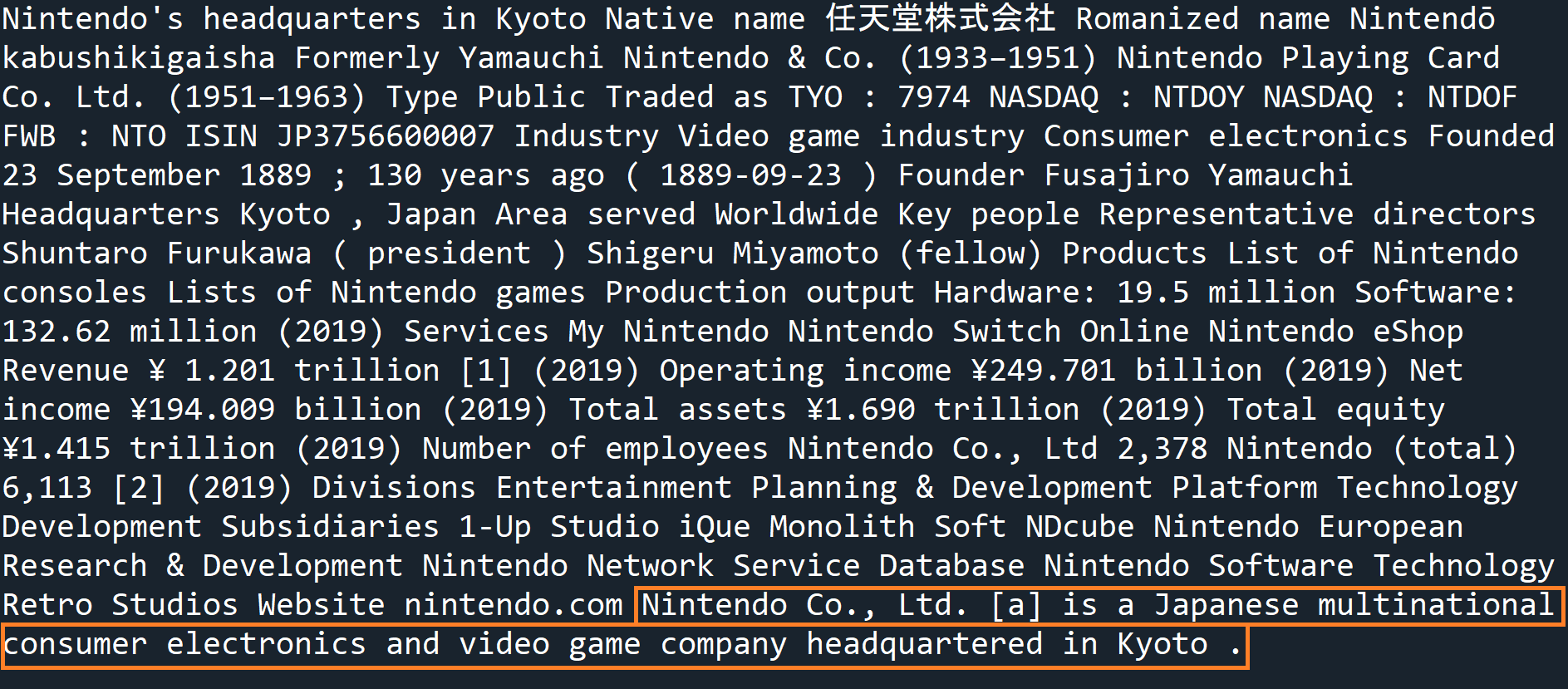
As you can see, we have the first sentence but there is also a lot of other text with it. This text is actually from the wikipedia information box, which does not have the necessary punctuation for NLTK to differentiate it.
Problems like this would need to be solved by manually splitting the long sentence up into the actual sentences we want.
For example, we could take this long sentence, split it up into words, then take only the words from the sentence we want. We could then concatenate these words back together, with a space in between each one to recreate the desired sentence.
sentences = sent_tokenize(text) sentence_words = sentences[6].split() first_sentence = ' '.join(sentence_words[-18:])
Here we use split the long sentence (sentences[2]) into a list of words and store them in sentence_words.
If we read the actual first sentence of the wikipedia page, we can count that there are 18 words (including the final period) in the sentence.
Therefore we use slicing to get the last 18 words of the long sentence (the actual words we want) and join them together with a space (' ') in between each word. This newly constructed sentence is then stored in the first_sentence variable.
Let's print this sentence to check that it is correct.
sentence_words = sentences[6].split() first_sentence = ' '.join(sentence_words[-18:]) print(first_sentence)

You may have also noticed that when we originally tokenized the sentences, words like 'Co.' or Ltd. did not split up the sentences even though they have a period.
This is why NLTK tokenization is so useful. It can clearly differentiate between punctuation used to end a sentence, and punctuation used in words.
Now let's try tokenizing our text into words using word_tokenize and passing in the original text as an argument.
sentence_words = sentences[2].split() first_sentence = ' '.join(sentence_words[-18:]) nltk_words = word_tokenize(text) print(nltk_words)
Just like with Python's split() function, words_tokenize() splits our text into a list of individual words.
Using split or NLTK to tokenize words depends on your needs and preferences. However, NLTK is the much preferred method for tokenizing sentences.
Another benefit of NLTK is that it can easily tokenize text from non-english languages. All you have to do is pass in the language of the text as another parameter.
nltk_words = word_tokenize(text) french_text = "Bonjour M. Adam, comment allez-vous? J'espère que tout va bien. Aujourd'hui est un bon jour." french_sentences = sent_tokenize(french_text,"french") print(french_sentences)

WordNet
When we installed NLTK packages using nltk.download(), one of those packages was WordNet.
WordNet is a database built for natural language processing that includes words with groups of synonyms and brief descriptions. It is basically a large dictionary for the English language, specifically designed for natural language processing.
Let's start by importing WordNet into the program.
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import wordnet
Now you can look up words using the wordnet.synsets() function by passing in a word as an argument.
This returns a list of Synset objects that each contain a word that is a homonym of the word passed into the function (as well as the original word itself)
When you pass in a word, NLTK will look up that word in WordNet. If a word cannot be found, the list will be empty. Some words only have one Synset, and some words have multiple.
french_sentences = sent_tokenize(french_text,"french")
syn = wordnet.synsets('boy')
Let's check how many Synsets were found for the word 'boy'. We can also print the list to see what was found.
syn = wordnet.synsets('boy')
print(len(syn))
print(syn)

As you can see, there are 4 Synsets for the word 'boy'.
We can use these Synset objects for many things. For example:
We can get the name of a Synset using the name() method.
We can get a definition of the word using the definition() method.
We can also get a list of examples of the word using the examples() method.
Remember that since the Synset objects are in a list, we have to index the Sysnet that we want.
syn = wordnet.synsets('boy')
print('Name: ', syn[0].name())
print('\nDefinition: ', syn[0].definition())
print('\nExamples: ', syn[0].examples())

Now let's take a look at the second Synset for the word 'boy' (index 1).
syn = wordnet.synsets('boy')
print('Name: ', syn[1].name())
print('\nDefinition: ', syn[1].definition())
print('\nExamples: ', syn[1].examples())

As you can see, this is still the word boy, but has a different meaning.
When two words have the same spelling and pronunciation but have different meanings, they are called homonyms.
WordNet can also be used to get synonymous words using the lemma() function. Let's find and print the synonyms for the word 'computer'
synonyms = []
for syn in wordnet.synsets('computer'):
for lemma in syn.lemmas():
synonyms.append(lemma.name())
print(synonyms)

The Lemmas() function returns a list of lemma objects. (We will look more at lemmas in the lemmatization section.)
In this example, we looped through the all the lemmas in each Synset for 'computer' and appended lemma.name() (the actual synonym) to the synonyms list.
We can also get antonyms of words in a similar way. We just have to check the lemmas to see if it's an antonym or not before appending it to the array. We can do this with the Lemma's antonyms() function.
antonyms = []
for syn in wordnet.synsets('small'):
for lemma in syn.lemmas():
if lemma.antonyms():
antonyms.append(lemma.antonyms()[0].name())
print(antonyms)

As you can see, we get a list of antonyms for the word 'small'. Sometimes we will get duplicate antonyms or synonyms because different Synsets may still have the same antonyms or synonyms.
Stemming
Stemming is the process of removing suffixes from words in order to normalize them and reduce them. What we are left with is the root or stem of the word.
For example, stemming the words computational, computed, and computing would all result in
computsince this is the non-changing part of the word.
There are many different algorithms for stemming and we can use NLTK to access these. The most used algorithm is the Porter stemming algorithm.
As always, we first have to import this module into our program.
from nltk.corpus import wordnet
from nltk.stem import PorterStemmer
First we have to create a PorterStemmer object, then we can use the stem() function to stem any word that we pass into it.
stemmer = PorterStemmer()
print(stemmer.stem('eating'))

As you can see, stemming the word 'eating' returns the word 'eat'.
Another algorithm we can use is the Snowball stemming algorithm. The SnowballStemmer can stem 15 languages besides English.
Let's import this module as well.
from nltk.stem import PorterStemmer
from nltk.stem import SnowballStemmer
We can check the supported languages using the languages attribute.
print(SnowballStemmer.languages)

To be able to stem with the SnowballStemmer, we have to create a SnowballStemmer object.
We can also specify what language we want to stem by passing it in as an argument.
french_stemmer = SnowballStemmer('french')
print(french_stemmer.stem("manger"))

Here we create a French SnowballStemmer and stem the word 'manger' (French for 'eat').
The word 'mang' is returned as the stem of 'manger'.
Lemmatization
We previously mentioned lemmas and lemmatization, so now let's explain exactly what they mean.
Lemmatization is similar to stemming but it takes context into account when creating the stems. It is more complex as it needs to look up and fetch the exact word from a dictionary to get its meaning before it can create the stem.
A lemma is just the root/dictionary form of a word. Stemming just returns the word with the suffix removed (whether the result is a word or not) while lemmatization returns the actual lemma (root) of the word.
As always, let's import the module that will be used. In this case, we can use WordNetLemmatizer from nltk.stem.
from nltk.stem import SnowballStemmer
from nltk.stem import WordNetLemmatizer
Now, let's create a WordNetLemmatizer object and use its lemmatize function on a word.
We can also compare this to the regular stemming of the same word.
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print('Stemming: ', stemmer.stem('increases'))
print('Lemmatizing: ', lemmatizer.lemmatize('increases'))

As you can see, stemming returns 'increas' by just removing the suffix 'es'. Whereas, lemmatization returns 'increase' because it looks up the word and finds the lemma (dictionary form).
Lemmatization might also return a synonym or a different word with the same meaning. Sometimes, if you try to lemmatize a word like the word 'playing', it will end up with the same word.
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing'))

This is because the default part of speech is nouns. Remember, a part of speech (POS) is just the role of the role of a word in a sentence. This can be:
Nouns - n
Verbs - v
Adjectives - a
Adverbs - r
Since 'playing' is a verb, we have to specify that it is a verb when lemmatizing it. We can do this by setting the pos parameter to 'v'
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize('playing', pos='v'))

Perfect! The word has now been lemmatized correctly as a verb.
Additional Data Sources
Now that you know how to clean up text data, you can find other data sources to use to perform this type of analysis.
Here are some data sources that you could use, but also feel free to look up your own!
Looking for something a little more fun? Here's some television scripts that you use to parse for their content as well. You can parse the text and create datasets which include all of the dialogue from the television show, to later use in a text-generation model.
Because these television shows have a limited cast of characters, you could potentially create each separate character as their own text-generation model that reacts based on what the character before said.