Machine Learning Classification
In this lesson, we'll get a taste of using python and machine learning to classify video game ratings and figure out if the reviewer liked or disliked a game.
Classification
Machine learning has many different applications. One common application is a text classifier.
For example, here's a few snippets of reviews for video games. Try to guess which of these games received a positive review score, and which of these games received a negative review score.
1. The Elder Scrolls IV: Oblivion -
The Elder Scrolls IV: Oblivion is simply one of the best role-playing games ever made.
2. Dragons and Titans -
Dragons and Titans is a halfhearted and frustrating online arena that doesn't deserve your time.
3. Ratchet & Clank -
Ratchet & Clank skillfully avoids most of the traps that hold back the majority of modern platform games and presents a fantastic, well-balanced, story-driven adventure.
4. Gas Guzzlers Combat Carnage -
Poor design decisions and lots of annoying little things mar this otherwise decent racer.
Based on these reviews, which games do you think received a positive review? Which games received a negative review?
Were your guesses right? Think for a minute how you came to that decision. After reading the descriptions, you might have picked out words that informed you about the quality of the game. Here are some examples of words that portray both positive and negative thinking.
Positive Words:
Best,
Fantastic,
Well-balanced
Negative Words:
Halfhearted,
Frustrating,
Poor,
Annoying
As people, we can read through text like this and understand whether the writer thinks positively or negatively about the topic. In this lesson, we're going to use classification and machine learning to teach a program to be able to read the text in the same way (mostly!)
Data Setup
We will be using this Scikit-Learn to perform our machine learning functions. This is an additional module that does not come default with Python (similar to Pandas and Matplotlib).
You should already have Sci-kit learn installed on your computer.
Create a new python file called machineLearningClassification.py.
Download the Gamespot Game Reviews dataset and place it in the same location as your python file.
At the top of your file, we will import modules related to the text classification process
Also read in the CSV file using the .read_csv() function.
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
dataframe = pd.read_csv("gamespot_game_reviews.csv")
The first time you read in the CSV file, it may take a little while, because your computer needs to take the information from your hard drive or solid state drive and store it in RAM. After the first time you read the data in, you may notice the code running faster until you exit out of python entirely and then try to run the code again.
Next, we'll start to look at the data set and structure it in a way we can use it for our machine learning purposes.
Data Analysis
Let's start by looking at all the columns in the dataset.
dataframe = pd.read_csv("gamespot_game_reviews.csv")
print(dataframe.columns)
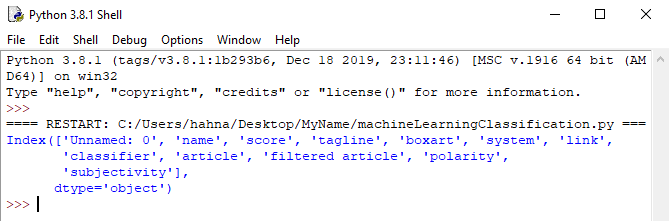
There's a lot of columns here. If we want to create a machine learning algorithm to determine whether a game review is positive or negative.
For the purposes of our classification, we're going to use two columns: 'tagline' and 'classifier'. We'll create a new dataframe that has just those columns.
dataframe = pd.read_csv("gamespot_game_reviews.csv")
reviews_dataframe = dataframe[['tagline', 'classifier']]
print(reviews_dataframe)

Based on the data, we can see that the tagline is a list of words that is used to describe the game, and the classifier is one of two values:
posor
neg, indicating a positive or negative review.
We will build the machine learning model to determine if a video game review is positive or negative based on the information in the tagline. That way, if we find any more game reviews, we can predict whether the review is positive or negative about the game.
You could use this algorithm to read through plain text on social media that does not include a specific positive or negative score and determine whether people are speaking positively or negatively about a game.
Next, we're going to need to break down the tagline field to get at the words which really matter for the classifier.
Understanding Text
You might have noticed two of our imports, CountVectorizer and TfidfTransformer. Each of these modules solves a specific problem for interpreting text.
First, we need a way to count how often words appear inside of a 'tagline' field. The CountVectorizer will count how many times a word appears in a specific line.
We will access all the information the
taglinecolumn of the dataframe and turn it into a giant list of individual words.
reviews_dataframe = dataframe[['tagline', 'classifier']]
tagline_list = reviews_dataframe['tagline'].tolist()
count_vect = CountVectorizer()
words_train_counts = count_vect.fit_transform(tagline_list)
print(words_train_counts)
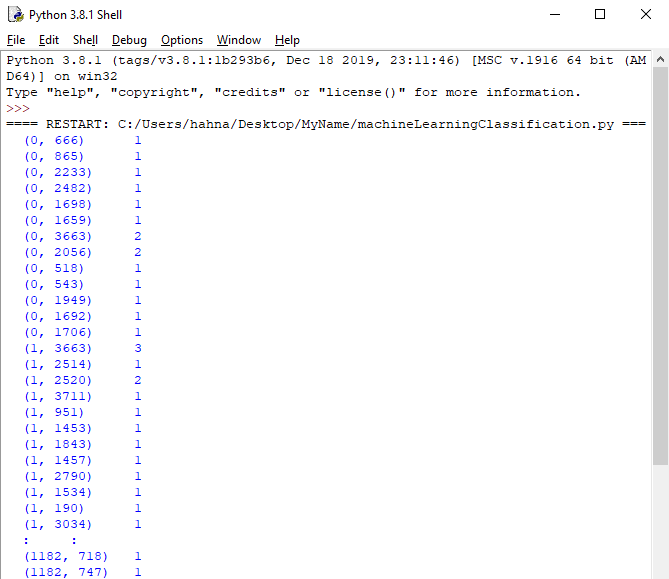
By using the CountVectorizer, we take the list of text strings, and count how many times a word appears in the string.
In order for the machine learning to occur, it takes all of the strings and transforms them into numbers. For example, the lines starting with
(0,each represent a different word in the first review in the dataset. The first review in the dataset is the following sentence.
Chrono Cross may not have had the largest budget, but it has the largest heart.
The results shows a tuple column and an integer column. The tuple contains two elements, the first element is the index of the tagline field, and the second is the word (represented as a number). The second column shows how many times the word appeared in that tagline.
You can see in the data that the words for
3663and
2056show up twice. By reading the tagline closely, you can see that there are only two words that are repeated twice:
largestand
the. This is how CountVectorizer is breaking down each tagline of the review data.
Next, we're going to set up information related to the weight of each word, or how often it appears in the text. We'll do this using TFIDF, or
Term Frequency -Inverse Document Frequency.
TFIDF will give each word an
importancescore. It uses a strategy of finding words that are shared across multiple taglines, but don't appear everywhere. For example, it will give a low weight to the word
thebecause it appears everywhere. But it will give a high weight to a word like
amazing, which isn't common to every single tagline, but is shared by 15 different reviews. That means it's an important word these reviews use to describe a particular quality of the game.
TFIDF determines a word's importance inside of a dataset, but it doesn't tell us whether the word means the game is good or bad. In fact, the word
terriblealso appears in 15 reviews, so TFIDF will give the words
amazingand
terriblethe exact same weight. Our machine learning algorithm will use these weights to determine which of these words indicates a positive or negative review.
words_train_counts = count_vect.fit_transform(tagline_list)
tfidf = TfidfTransformer()
words_train_tfidf = tfidf.fit_transform(words_train_counts)
#This will show us how many rows and how many columns the dataset has
print(words_train_tfidf.shape)
##Result
##(1184, 4139)
#This will show us an example of what the columns look like
print(words_train_tfidf.data)
##Result
##[0.12666006 0.18338277 0.21286579 ... 0.16532873 0.27479679 0.39429255]
By looking at the shape of the data, we can see that the data set now has 1184 rows and 4139 columns. Those 4139 columns represent every single word that was found in any of the taglines.
With our data ready to go, we can now start to do our machine learning on this data set.
The Result shows the relationship of that word to the classification. If the number is higher, then that word has a greater correlation to the review being a 1, since it is positive.
Train, Test, Predict
It's one thing to train a machine learning model and then try to use that trained model for predictions. It's another problem to know whether or not your model's prediction had any merit. Machine learning isn't an exact science, but instead is based on reasonable predictions. We don't expect the computer to perfectly classify everything we give it.
In order to make sure that our machine learning model is working correctly, we will use a method called splitting the data set.
We won't train our model on the entire data set at once. Instead, we'll use a portion of the data set and leave the rest of the data alone. Why do we do this? After we train our model, we can try to predict the results of the remainder of the data set. Then, we can determine how correct our model is.
We're going to use the train_test_split() function to split up our data into different parts. This function takes in 3 arguments, the data set we want to check(our list of words and their relevance to results), the result that we want to check for(whether a review was positive or negative), and the size of the test data after the data split(what percentage of data do we want to reserve to test on at the end).
When you pick the test size, if you don't pick the right size, there might be larger margin of error in your classifications.
If you have too large of a test size, you won't have enough data to train your model. If you have too small of a test size, then when you test the model there might be a certain amount of randomness that will show up in your tests, so you won't be able to determine whether your model is accurate or not.
words_train_tfidf = TfidfTransformer().fit_transform(words_train_counts)
split_results = train_test_split(words_train_tfidf, np.array(reviews_dataframe['classifier']), test_size=0.3)
train_words = split_results[0]
test_words = split_results[1]
train_reviews = split_results[2]
test_reviews = split_results[3]
The last step is to actually apply the machine learning model, and perform predictions using our test data.
To create the model, you need to give the MultinomialNB's fit method both the words that will be used to make the prediction, and the classifications that have already been made.
You run the classification model's predict function on our test words. Since we will already know the correct review results, we can store that information and check to see the prediction's results line up with the correct results.
test_reviews = split_results[3] classification_model = MultinomialNB().fit(train_words, train_reviews) testing_score = classification_model.predict(test_words) print(testing_score)
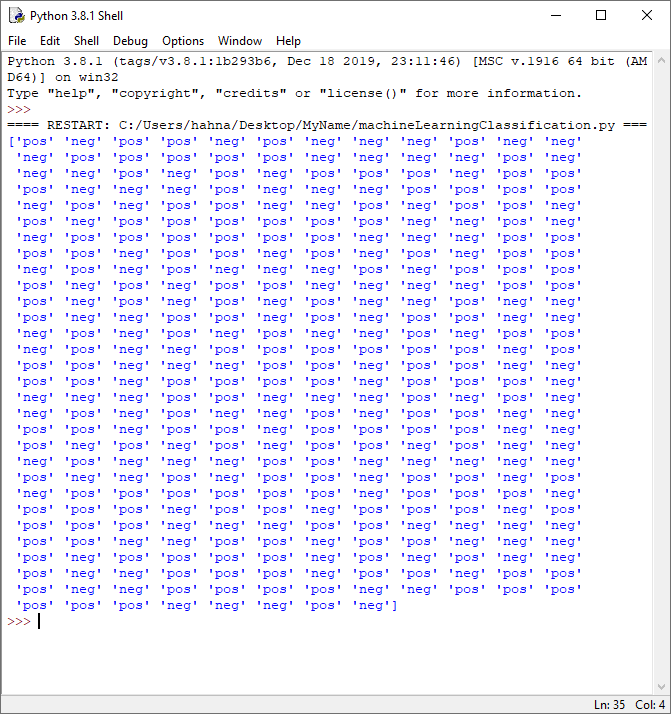
In the output for testing_score we see the results of the prediction. We can compare these against the test data set to determine the accuracy of our model.
testing_score = classification_model.predict(test_words)
number_right = 0
for i in range(len(testing_score)):
if testing_score[i] == test_reviews[i]:
number_right +=1
print("Accuracy for tagline classify: %.2f%%" % ((number_right/float(len(test_reviews)) * 100)))
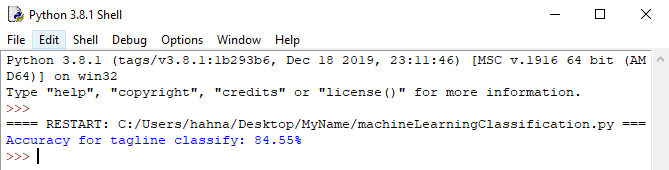
You should see a result around 85% accuracy. It may be slightly different every time you run the program, since the train/test split may split the data up differently each time.
Additional Challenges
Improving Accuracy
You didn't perform any data cleanup when it came to this dataset. Sometimes, it can be worth it to clean up the data before putting it into the machine learning algorithm to improve its accuracy.
Try to clean up the dataset by performing some of the steps listed in the Natural Language Processing Lesson, such as removing stop words and stemming the text.
In addition, some of the rows are duplicates, because the exact same review is given for two different consoles. Removing these duplicates might improve your results.
Custom Input
1. Create a list with your own game reviews.
2. Use the transform() function from count_vect instead of the fit_transform() function on your list.
3. Use the transform() function from tfidf instead of the fit_transform() function on the count vectorizer's results.
4. Insert those results into the classification_model.predict() function.
5. Print your results. Did the model predict correctly? Try writing some reviews that will be confusing for it to interpret.
User Input
Have your program take input from the user and display the results of the prediction back to them.
Additional Data Sets
In the Dataset Analysis lesson, you found a dataset that could be used as input for a classification algorithm. Try to implement a text classification process for the dataset you picked out or take a look through the Kaggle Datasets and see if there are any data sets that would also make a good test for training a machine-learning model.